Unique ID Generation
Problem Statement
The Maelstrom server will send a generate message with the following format:
{
"type": "generate"
}and we need to reply with the following message:
{
"type": "generate_ok",
"id": 123
}The ID in our response should be globally unique, and our system should continue to function even if the network is down or our node has been disconnected from the network.
Solution
Let’s start very simple. What would happen if we just send back the current timestamp?
GenerateUniqueIdPayload::Generate {} => {
let message_id = message.body.id;
let message = Message {
src: message.src,
dest: message.dest,
body: Body {
id: message.body.id,
in_reply_to: message.body.in_reply_to,
payload: GenerateUniqueIdPayload::GenerateOk {
id: SystemTime::now().duration_since(UNIX_EPOCH).unwrap().to_string(),
},
},
};
message.into_reply(Some(&mut message_id.unwrap())).send(output)?;
}We just use the standard SystemTime struct that Rust provides, and return the current time since the unix epoch. How does this fare?
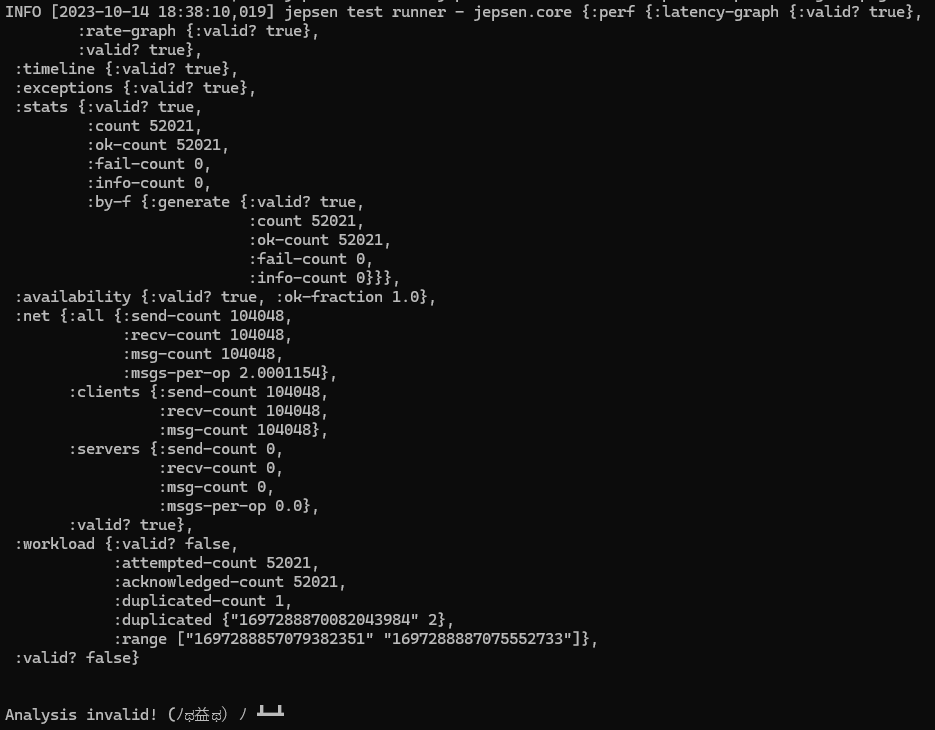
Pretty good!
We only had one duplicate while running our test bench. But, as this system scales further, and we get more requests concurrently, we’re sure to run into an increasing number of duplicates.
So what do we do?
The most obvious thing that springs to mind is to use UUIDs! These are 128-bit globally unique identifiers. Let’s try them out.
Does it work? Yep!
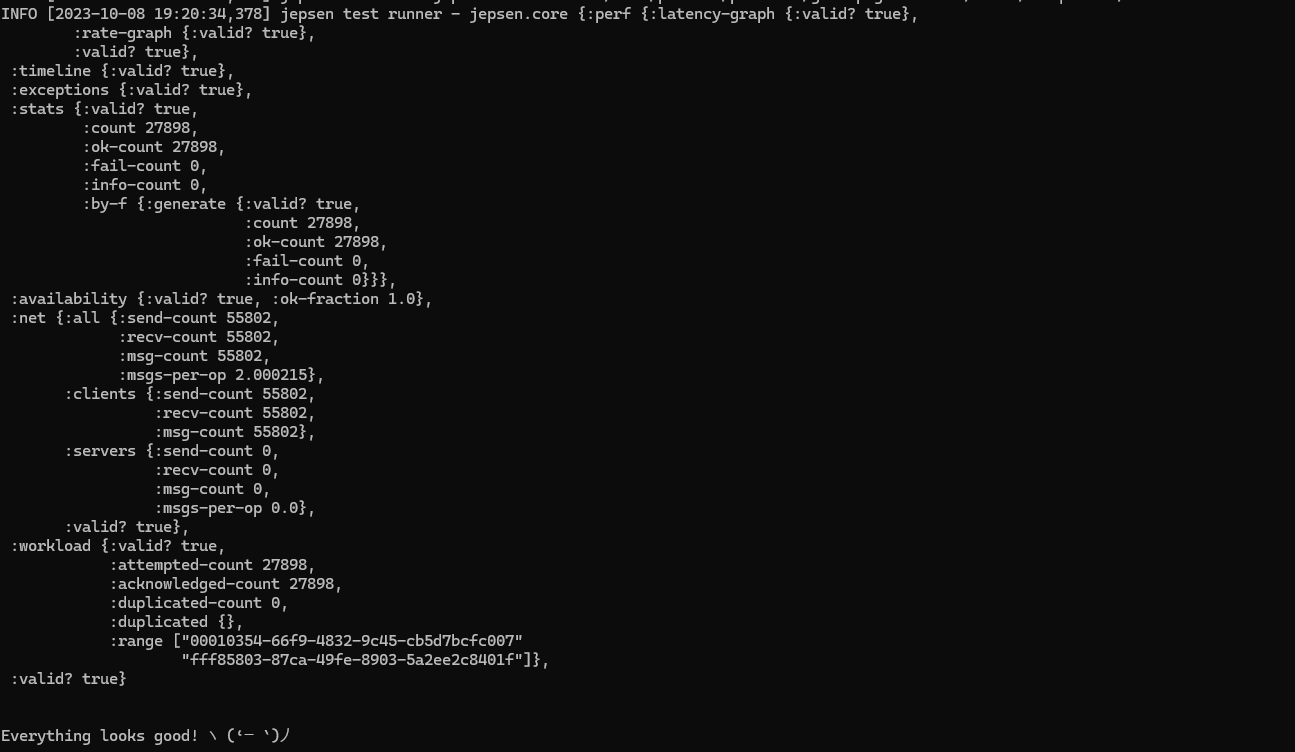
But this makes the solution for the problem a little too simple.
Let’s instead try implementing the UUID specification ourselves.
UUID
A UUID is a 128-bit identifier that is statistically guaranteed to be globally unique. They can definitely generate duplicates, but this excerpt from wikipedia sheds some light on how unlikely that is
the annual risk of a given person being hit by a meteorite is estimated to be one chance in 17 billion, which means the probability is about 0.00000000006 (6 × 10−11), equivalent to the odds of creating a few tens of trillions of UUIDs in a year and having one duplicate. In other words, only after generating 1 billion UUIDs every second for approximately 100 years would the probability of creating a single duplicate reach 50%.
Apart from the randomness guarantees, what makes UUIDs so appealing?
- No centralized authorities are required to create UUIDs
We do not need a central server/API/backend to generate these UUIDs. They are guaranteed to be unique regardless of where they are generated
- In practice, this means that clients can generate them as well!
- Fixed size - 128-bits
ULIDs
There is an alternative to UUIDs, called ULID (Universally Unique Lexicographically Sortable Identifier) that does not guarantee the same level of global unique-ness but generates random IDs that are lexicographically sortable.
UUID Format
Let’s dive into the format of a UUID. We’ll be mainly concerned with UUIDv1 and UUIDv4 (UUIDv4 is truly random, while v1 has some parts of it that are static and hence guessable).
Byte Order
A UUID is laid out in the following way -

1. Components of a UUID
time_low: uint32, bytes 0-3, the low field of the timestamp.time_mid: uint16, bytes 4-5, the middle field of the timestamp.time_hi_and_version: uint16, bytes 6-7, high field of timestamp multiplexed with version. bits 4-7 encode the UUID version.clock_seq_hi_and_reserved: uint8, byte 8, high field of the clock sequence, multiplexed with variant.clock_seq_low: uint8, byte 9, low field of the clock sequence.node: uint48, bytes 10-15, a spatially unique node identifier.
2. Algorithmic Approach
Basic Algorithm
- Take a system-wide lock, along with a shared state file containing timestamp, clock sequence, and node ID.
- Retrieve the current timestamp and node ID.
- If the timestamp stored in the state file is later than the current timestamp, something has gone wrong with the system clock. When this happens, we increment the clock sequence to ensure a degree of randomness while the system clock catches up.
- Then, derive all the required fields in the byte order using this information
- Update the state file and release the lock.
- Generate the UUID using the order laid out in the spec.
3. Addressing Challenges
I. Efficient State Management
Challenge: We continuously read/write the state to the file on disk, which is inefficient.
Solution: Read state only once at boot time, if it can be kept in a system-wide shared volatile store.
From my understanding, this encourages using a shared block of memory (across processes?) that gets updated as new UUIDs are generated. Processes only need to read from the state file on boot, and there can be a background process that syncs data from the memory to the state file.
II. Timestamp Generation
Challenge: Not all systems provide timestamps with nanosecond precision, which UUIDs use to reduce the chance of collisions.
Solution:
-
If UUIDs don’t need frequent generation, it can simply be the system time multiplied by the number of 100-nanosecond intervals per system time interval. So, if your system provides timestamps with microsecond level precision, we multiply the timestamp by
10(because there are 10 100-nanosecond intervals per microsecond). If the system overruns the generator by requesting too many UUIDs within a single system time interval, the UUID generator MUST either return an error, or block until the system clock catches up. This (if I understand correctly) will essentially limit you to 10 UUIDs per microsecond tick. -
A high-resolution timestamp can be simulated by keeping count of the number of UUIDs that have been generated with the same value of system time, and using it to construct the low order bits of the timestamp. The count will range between zero and the number of 100-nanosecond intervals per system time interval (for eg., 0-10 for a microsecond system time tick)
III. Cross-Process State Sharing
Challenge: Synchronizing state management across multiple processes.
The “global” lock that we maintain over the state file is taken by the process. If the state file is used by other processes generating their own UUIDs, we need some kind of synchronization across these processes which would usually be done via IPC (inter-process communication), so that these processes can tell each other about the locks that they’ve taken on the file.
Solution:
Use IPC to sync lock information across processes. But we need to be careful here, as IPC will add quite a bit of overhead.
Bit manipulation!
One of the fascinating things that I learned during this process was how to manipulate bits using bitmasks. Let’s go over an example to see how this is done.
time_hi_and_version
The time_hi_and_version field has the following byte order -
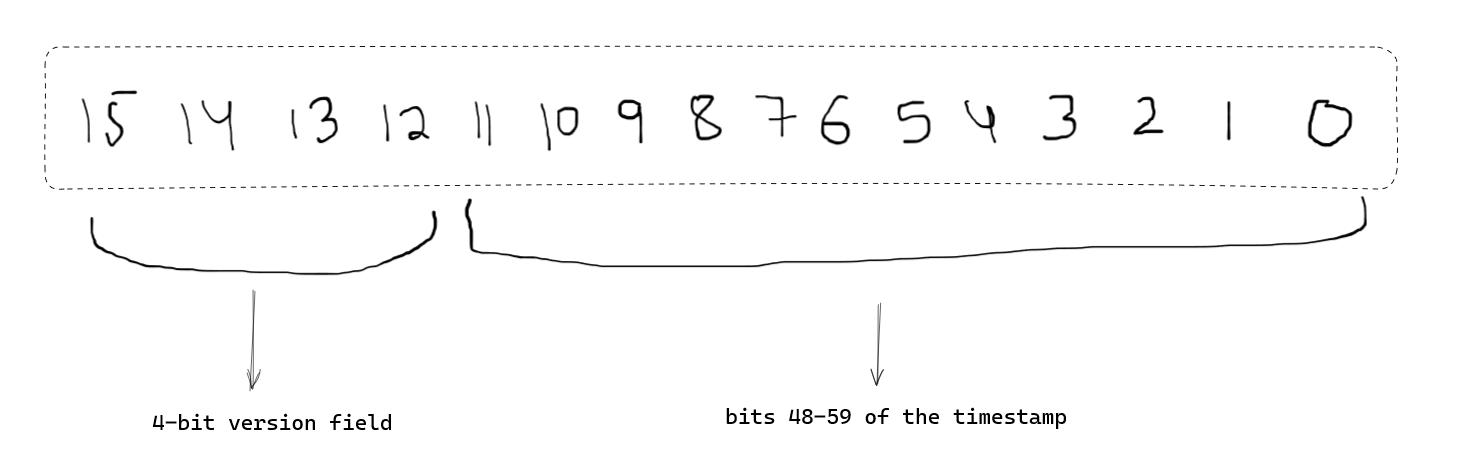
How do we get these particular bits into this field? Bitmasks!
What is a bitmask?
A mask or bitmask is data that is used for bitwise operations. Using a mask, multiple bits in a byte can be set either on or off, or inverted from on to off (or vice versa) in a single bitwise operation.
If you had a byte of all 1s - 1111_1111 and you wanted to conserve bits 0-4, include them in your own set of bits, and discard the rest of the bits, how would you do that?
We could create a bitmask which will help us do this.
1111 1111
AND 0000 1111 (this is our bitmask)
0000 1111
if we do an AND operation with a bitmask which has 1s in the locations that we need, we’ll only keep those bits, and the rest of them will be set to 0.
Now, let’s consider the time_hi_and_version field. The timestamp is a 60-bit field, and we want to extract bits 48-59.
The first thing we do, is create a time_hi_mask field with the following layout - 0000_1111_1111_1111.
Then, we shift the timestamp field to the right by 48 bits. This moves the first 12 bits to the right 48 times, padding the left side with 0s as it goes.
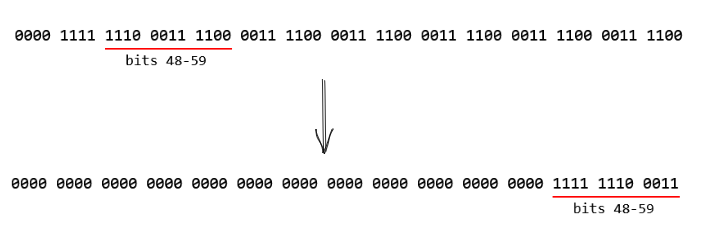
Now, we have the bits we need at the end of our timestamp field. We can then do an AND with our time_hi_and_version variable, which will set the last 12 bits of time_hi_and_version to bits 48-59 of the timestamp field.
0000 1111 1111 1111 (the `time_hi_mask` data)
AND 0000 1111 1110 0011 (right-shifted `timestamp` data)
-------------------
0000 1111 1110 0011 (we've successfully extracted these bits into `time_hi_and_version`)
Next, we need the first 4 bits to be set to the version. In our case, we’re generating a v1 UUID, so we do the following bit operation
0000 1111 1110 0011 (the `time_hi_and_version` data)
OR 0001 0000 0000 0000 (a `version` bitmask)
-------------------
0001 1111 1110 0011 (the final `time_hi_and_version` data)
We’ve successfully created the time_hi_and_version field! This is the final code -
fn get_time_hi_and_version(&mut self) -> u16 {
let current_timestamp = self.state.last_timestamp;
let mut time_hi_and_version = 0b0000_1111_1111_1111;
/*
we need timestamp bits 48 through 59
we shift the timestamp by 48 bits, giving us bits 48 through 63
*/
let shifted_timestamp = current_timestamp >> 48;
let time_hi_mask = 0b0000_1111_1111_1111;
let required_timestamp_bits = (shifted_timestamp & time_hi_mask) as u16;
/* put bits 48-59 into the end of time_and_hi_version */
time_hi_and_version &= required_timestamp_bits;
/* 0100 is version 4 - which is what we want to generate */
let version: u16 = 0b0001_0000_0000_0000;
time_hi_and_version | version
}Conclusion
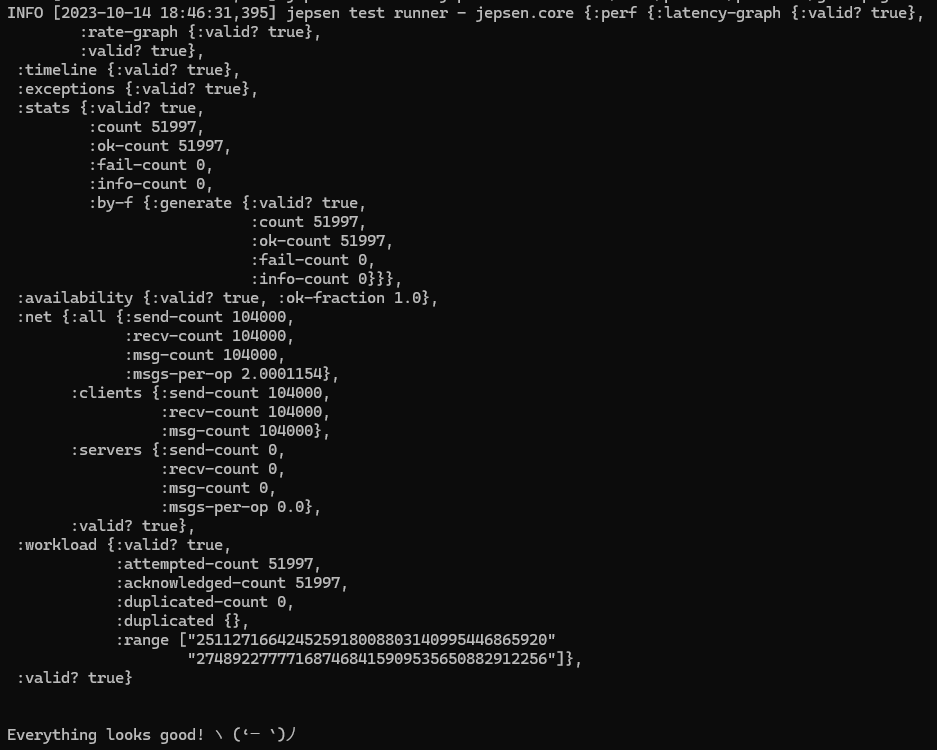
We’ve now implemented our own version of the UUID v1 spec! Does it solve our problem?
Yes!
You can find the completed code for the implementation of the UUID spec on my GitHub here.